序数回归(Ordinal Regression)是一种处理有序类别因变量的数据分析方法,它可以用来分析自变量与因变量之间的关系,尤其当因变量是有序的(例如评分等级:低、中、高)时。与普通的线性回归不同,序数回归考虑了因变量的有序性,因此在分析中可以为每个类别赋予一定的顺序。
在SPSS中进行序数回归分析,研究人员能够分析多种自变量(无论是连续的还是分类的)对有序因变量的影响,并通过模型的系数推断因变量的变化趋势。本文将为您介绍序数回归的基本概念,并教您如何通过SPSS进行序数回归分析。
1. 序数回归分析概述
序数回归用于有序因变量的回归分析。例如,假设一个调查问卷要求受访者根据产品满意度给出评分,评分等级为“非常不满意、一般、非常满意”。这里,满意度属于有序因变量(有明确的等级顺序),因此可以使用序数回归来建模。
与线性回归不同,序数回归模型关注的是类别的顺序而非数值之间的差异。在序数回归中,因变量的不同级别是有序的,但级别之间的间隔不一定是等距的,因此模型需要专门处理这个顺序信息。
常见的序数回归模型包括Proportional Odds Model(比例赔率模型),它假设所有因变量的类别之间有相同的回归系数。
2. 如何使用SPSS进行序数回归分析
在SPSS中,进行序数回归分析非常简单。通过SPSS的“回归”模块,您可以轻松地构建和解释序数回归模型。以下是具体的操作步骤:
步骤一:准备数据集
首先,确保您的数据集已经加载到SPSS中。对于序数回归分析,您需要确保因变量是有序的类别数据。例如,因变量可以是一个“满意度”变量,取值为“非常不满意(1)”,“一般(2)”,“非常满意(3)”。
步骤二:选择回归分析

在SPSS的菜单中,点击:
分析(Analyze)选择 回归(Regression)然后选择 序数(Ordinal)。
步骤三:选择因变量和自变量
在弹出的对话框中,您需要设置因变量和自变量:
因变量(Dependent):将有序的因变量(如“满意度”)拖入此框。自变量(Independent(s)):将影响因变量的自变量(如年龄、收入、广告支出等)拖入此框。
步骤四:设置模型选项
SPSS允许您根据需要选择不同的回归选项:
方法(Method):通常选择“Enter”方法,这意味着所有自变量将一起进入模型。选项(Options):您可以选择显示回归系数、标准误差、模型拟合优度等统计量。此外,您还可以选择是否显示显著性检验和效应大小。
步骤五:运行分析并查看结果
点击**确定(OK)**后,SPSS将执行序数回归分析,并生成一系列结果,包括模型拟合度、回归系数、比例赔率和显著性检验等。以下是分析结果的主要内容:
3. 解读SPSS序数回归分析结果
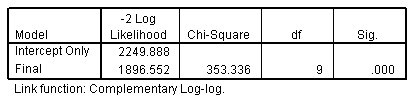

SPSS输出的结果包含几个重要部分,帮助您解读序数回归模型的效果和统计显著性。
1. 模型拟合度(Model Fitting)
SPSS会提供一个“模型拟合”部分,包括像**-2 Log Likelihood和Chi-square**检验的统计量。此部分用来判断回归模型是否适合数据。一个显著的Chi-square值通常表示模型能有效拟合数据。
2. 回归系数(Coefficients)
回归系数表显示了每个自变量的比值比(Odds Ratio)、标准误差、z值和p值。其中:
比值比(Odds Ratio):表示自变量对因变量某个类别的影响。例如,如果比值比大于1,说明自变量的增加会使因变量增加某一类别的概率。p值:用于检验回归系数的显著性。如果p值小于0.05,表示该自变量对因变量有显著影响。
3. 预测概率(Predicted Probabilities)
SPSS还会提供预测概率,这些概率反映了在给定自变量值的情况下,因变量落入不同类别的可能性。这部分结果帮助您理解模型的预测能力。
4. 残差(Residuals)
残差表帮助您评估模型的拟合情况。通过残差分析,您可以检查是否存在非线性关系、异方差性等问题。
4. 序数回归的应用场景
序数回归常用于处理那些有序类别的因变量,广泛应用于以下领域:
市场研究:分析消费者的满意度调查,预测消费者购买意图。教育研究:分析学生的成绩分类与学习行为、背景因素之间的关系。社会学研究:研究社会阶层、收入等有序变量与其他社会经济因素的关联。
5. 总结
序数回归是分析有序类别因变量的重要统计方法,能够帮助研究人员探讨自变量对因变量的影响。通过SPSS,您可以轻松进行序数回归分析,解读回归系数、预测概率,并优化模型预测。在市场研究、教育研究等领域,序数回归具有广泛的应用。
希望本文能帮助您理解序数回归的基本概念以及如何使用SPSS进行分析。如果您有任何疑问或进一步的问题,欢迎与我们联系。
